Why don't I get the throughput I benchmarked?
In synthetic benchmarks, you can achieve a high throughput for your system by throwing lots of independant tasks/clients at it to see what the theoretical limit of your system is, however in real world situations, the throughput you achieve is often much, much lower. One of of the explanations for this comes from Little’s Law
What is Little’s Law?
This law comes from queuing theory, an example being the number of customers in a store.
Little's Law tells us that the average number of customers in the store L, is the effective arrival rate λ, times the average time that a customer spends in the store W
L=λ × W
For a given latency, the higher the throughput you need to achieve, the higher the number of independant tasks you need. Say you have a shop where checking out at an automatic till takes 10 minutes on average. To achieve, a given throughput, how many tills, and people wanting to check out do you need?
Throughput |
People trying to check out at once |
1 every 10 minutes |
1 person and 1 till |
1 per minute |
10 people and 10 tills |
10 per minute |
100 people and 100 tills |
There might not be 10 or 100 people trying to check out at once, so even if you have the tills, there might not be enough people/users to utlise the tills you have.
Say instead it only takes 1 minute to pass through a till, how many people do you need to be checking out at once to get the throughput you are looking for.
Throughput |
People trying to check out at once |
1 every 10 minutes |
1 person and 1 till |
1 per minute |
1 person and 1 till |
10 per minute |
10 people and 10 tills |
Reducing the latency by a factor of 10 means you need one tenth of the resources. More importantly, you only need one tenth of the people trying to check out/tasks to achieve the desired throughput.
| Some problems have inherent limits to the number of independant tasks you have. Trading systems and business applications might only have an intrinsic concurrency of between 1 and 10, in which case, latency rather than throughput is your main constraint. |
Chronicle Queue vs Apache Kafka
On the surface, Chronicle Queue and Apache Kafka do many of the same things. They are both high throughput, persisted queues. What difference do Chronicle’s much lower latencies make?
In this benchmark, Apache Kafka achieved a throughput of around 400,000/s - 800,000/s on one machine, with linear scalability to three machines. This is a very good throughput. However the latency measured 2 ms and the 99%ile was 3 ms. This means any individual task which must wait for replication before proceeding must wait around 2 milli-seconds, or more conservatively 3 milli-seconds.
If the latency is 3 milli-seconds, how many independant tasks do you need to have to reach a desired throughput?
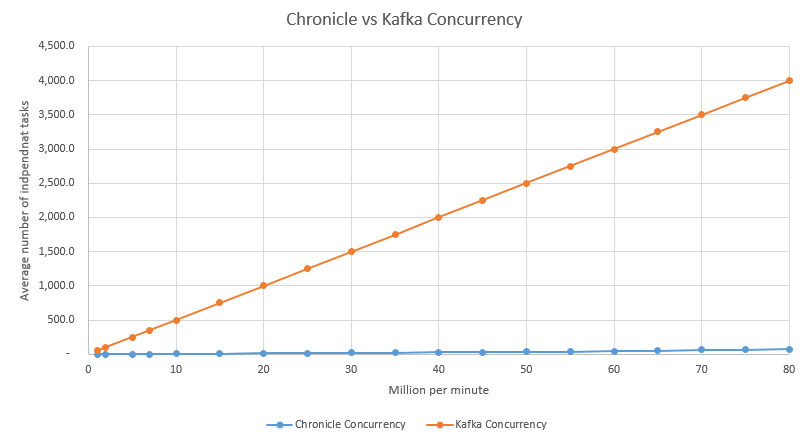
To achieve higher throughputs, you need more independant tasks. What if you only have 1 to 100 independant tasks?
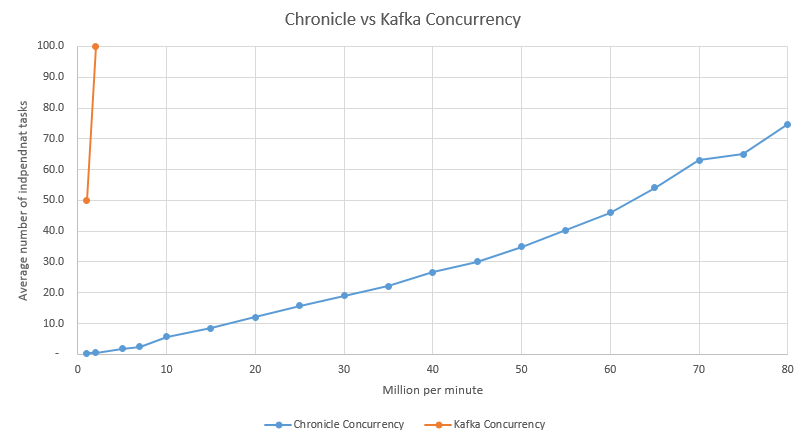
With a small set of tasks, you are not going to achieve a high throughput with a latency of 3 ms. By comparison if we look at the 99%ile latency of Chroncile Queue synchronous replication, which is between 20 - 40 micro-seconds, you can achieve high throughputs with relatively few independant tasks.
Independant Task(s) |
Chronicle Queue Throughput |
Apache Kafka Throughput |
1 |
50,000 per second |
340 per second |
10 |
290,000 per second |
3,400 per second |
100 |
2,000,000 per second (2 servers) |
34,000 per second |
To achieve, the benchmark throughput with Kafka, you need a problem which has a very high number of independant tasks (many thousands), or you either need asynchronous replication.
If asynchronous replication is acceptable, then Chronicle Queue has a much lower latency of 1.2 micro-seconds for the 99%ile. This means it can support close to one million messages per second with a single thread and only one task at a time. Two threads are enough to get 80 million events per minute which is our benchmark throughput for the E5-2650 v2 server we tested.
When do I add monitoring to my application?
Apache Kafka was designed for web application monitoring. It is widely used for this purpose today. As such it does the job very well.
However, Chronicle Queue is design to be fast enough to be part of the critical path, recording all the inputs and outputs of your services. Since you are already recording all the data needed to recreate the state of your component at any point, little additional monitoring is required. (System monitoring is still required) It is not a case of; Now our application is in production, how do we monitor it? Or how do we replay message to recreate an issue?
Chronicle Queue is integral to the working of the application so you know no information is missing or the application wouldn’t work.
Conclusion
If you have a problem with many thousands of independant tasks, then high number of tasks "in flight", or customers in the store, is a relatively simple way to get the throughput you need and the impact of latency is low. If you have a few tasks, or just one task you can perform at a given moment, latency rather than throughput is critical.