Micro-services for performance
Overview
Microservices is a buzz word at the moment. Is it really something original or based on established best practices? There are some disadvantages to the way microservices have been implemented, but can these be solved?
Component testability and consistency
Once you have assembled a large system, it can be hard or even impossible to profile where the highest delays come from. You can profile for average latency or throughput, but to achieve consistent latencies, you need to analyse key portions of your system. This is where having simple components which run independently, and can be tested as stand alone, could help you achieve the consistency of your system needs end to end.
The UNIX Philosophy
Many of the key concepts of microservices have been used in distributed systems for many years.
Microservices have much in common with the Unix Philosophy[1]
Mike Gancarz[2] is quoted as summed these principles as follows:
Small is beautiful.
Make each program do one thing well.
Build a prototype as soon as possible.
Choose portability over efficiency.
Store data in flat text files.
Use software leverage to your advantage.
Use shell scripts[3] to increase leverage and portability.
Avoid captive user interfaces.
Make every program a filter.
The Microservices Architecture[4] is the UNIX Philosophy applied to distributed systems.
Philosophy of microservices architecture essentially equals the Unix philosophy of "Do one thing and do it well". It is described as follows:
The services are small - fine-grained to perform a single function.
The organization culture should embrace automation of deployment and testing. This eases the burden on management and operations.
The culture and design principles should embrace failure and faults, similar to anti-fragile systems.
Each service is elastic, resilient, composable, minimal, and complete.
There are disadvantages[5] to using a microservices archictecture some of which are;
The architecture introduces additional complexity and new problems to deal with, such as network latency, message formats[7], load balancing [8] and fault tolerance[9]. Ignoring one of these belongs to the "fallacies of distributed computing".
Testing and deployment are more complicated.
The complexity of a monolithic application[10] is only shifted into the network, but persists.
Too-fine-grained microservices have been criticized as an anti-pattern.
Can we get the best features of a monolith, and micro-services? Does it have to be one or the other? Should we not use the approach which best suits our problem. One of the key aspects of Micro-services is controlled deployment of an application. In which case, shouldn’t we be able to deploy components as a Monolith or Micro-services where it makes the most sense to do so.
Proposed alternatives to nanoservices include;
Package the functionality as a library, rather than a service.
Combine the functionality with other functionalities, producing a more substantial, useful service.
Refactor the system, putting the functionality in other services or redesigning the system.
How can we get the best of both worlds?
Make sure your components are composable.
If your components are composable, then they are always the right size. You can combine them as needed into a collection of services, or everything into one service.
This is particularly important for testing and debugging. You need to know a group of business components work together without the infrastructure (eg. Middleware) getting in the way. For the purposes of a unit test, you may want to run all your components in one thread and have one directly call the other. This can be no more complicated than testing components of a monolith where you can step through your code from one component to another and see exactly what is happening.
Only once your components work together correctly without infrastructure, do you need to test how they behave with infrastructure.
Make your infrastructure as fast as your application needs.
Low latency trading systems are distributed systems, and yet they also have very stringent latency requirements. Most trading systems are designed to care about latencies much faster than you can see. In the Java space, it is not unusual to see a trading system which needs to have latencies below 100 micro-seconds, 99% of the time or even 99.9% of the time. This can be achieved using commodity hardware in a high level language like Java.
The keys to achieving low latencies are;
-
low latency infrastructure for messaging and logging. Ideally around a 1 micro-second for short messages,
-
a minimum of network hops,
-
a high level of reproduceability of real production load so you can study the 99%tile (worst 1 %) or 99.9%tile (worst 0.1%) latencies,
-
viewing each CPU core as having a specific task/service, with it’s own CPU cache data and code. The focus is on the distribution of your application between cores (rather than between computers).
Your L2 cache coherence bus is your messaging layer between high performance services.
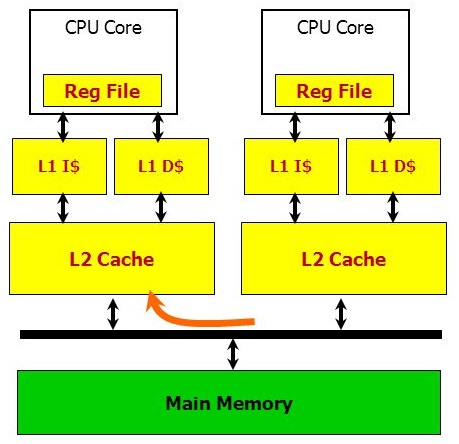
You can perform a CAS operation on the same data between two different cores. Here, each thread toggles the value set by the other thread with a round trip time of less than 50 nano-seconds on Sandy Bridge processors[11], less on newer generations.
Examples of low latency instructure in Java are;
-
Chronicle Queue - A persisted queue for messaging and logging.
These transports have different advantages in terms of handling load balancing and failover.
Make the message format a configuration consideration.
There is a number of competing concerns in message formats. You want;
-
Human readability so you can validate the messages are not only behaving correctly, but doing so in the manner you expect. I am often surprised how many issues I find by dumping a storage file or the message logs.
-
Machine friendly binary format for speed.
-
Flexability in terms of future schema changes. Flexability means adding redundancy so the software can cope with adding/removing fields and changing their data types in future. This redundancy is a waste if you don’t need it.
Ideally, you can choose the best option at testing/deployment time.
Some examples of serialization libraries where you can change the actual wire format to suit your needs are:
-
Jackson Speaming API[13] - Which supports JSON, XML, CSV, CBOR (a binary format),
-
Chronicle Wire - Which supports object serialization YAML, a number of different forms of Binary YAML, JSON, CSV, Raw data.
Conclusion
I think there is a lot of good ideas on how to use microservices, and I think many of the criticisms around them are based on how they have been implemented and I believe they are solvable.
Glossary
CPU core- "A processor core is a processing unit which reads in instructions to perform specific actions."[15]
Debugging- the process of searching for and fixing defects in code.
Distributed System- A collection of autonomous computers linked in a network by middleware[16]. A test can be distributed between a number of systems.
Failover- "A backup operation that automatically switches to a standby server or network if the primary system fails or is temporarily shut down for servicing."[17]
Latency- The time an individual operation takes. "Together, latency and bandwidth define the speed and capacity of a network."[18]
Microservices- Independantly deployable programmes that act as components in a larger network.
Throughput- The rate of data or messages transferred which is processed in a certain amount of time. This rate is written in terms of throughput, e.g a road could have a throughput of 10 cars per minute.
Serialization libraries- The process that translates data into a format that can be consumed by another system.
Wire format- A defined way for sending data between mechines as bytes.